DEVELOPMENTS
Disruption for Good
Dec 8, 2014
Despite the advances in human development in the 20th century, humanitarian aid remains as relevant as ever. While our ability to respond to disaster has improved, factors such as climate change and the burgeoning global population mean that the number and severity of disasters have also increased. Could “big data” help humanitarian relief actors keep up with this escalating challenge?
A Conceptual Framework
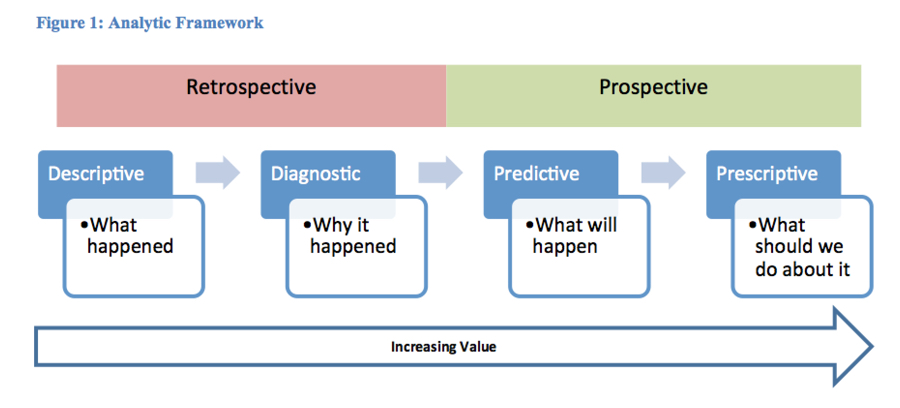
In examining how big data may disrupt the field of humanitarian aid, we can make use of Andrew Beale’s breakdown of data analysis into four processes—description, diagnosis, prediction, or prescription—while noting that the latter two elements are potentially more valuable because they guide future action.1 The resulting framework is shown in Figure 1.
Another axis along which big data initiatives vary is the source of the data. In responding to the H1N1 virus, for example, Google drew on its proprietary database of search terms. By contrast, DevTracker is creating a completely open dataset. The data analysed can also be drawn from an existing dataset (such as Google’s search data) applied to a secondary use, or can be generated specifically for the purpose at hand. Ushahidi users generate data on demand, in part because they know they will be able to use the resulting analysis. All things being equal, freely available datasets are more attractive than closed, expensive, or purpose-built datasets; and where data does not exist, crowdsourcing is more attractive than donors or other agencies creating new datasets. It is not hard to imagine some ways in which big data could change relief work in the near term and beyond.
Descriptive—What Happened
One of the major challenges in aid work is to quickly describe the extent of a disaster and its effects on people, infrastructure, and services.
In the case of a rapid-onset disaster such as an earthquake, for example, seismologists may immediately be able to pinpoint the quake’s severity and epicentre. But responders rely on slower, more labour-intensive methods to assess the number of casualties, the physical damage, and the impact on critical services. Most of this data is collected by responders themselves, using aerial surveys, satellite imagery, and on-the-ground, village-by-village reconnaissance, which is then mapped against census data or other information.
These are not existing, open, freely available datasets; the data collection is slow, expensive, and possibly inaccurate. Especially in the critical first 72 hours, when the first wave of mortality can be mitigated, response efforts are carried out almost blind, with relief provided where responders can readily gain access, rather than where it is most needed.
Big data might offer better tools for understanding the aftermath of a disaster. For instance, at the moment, satellite or other aerial photography that shows damage to physical infrastructure is generally analysed by visual inspection. However, the volume of imagery that can be produced is enormous. Military-grade, automated visual processing of this data could speed up and improve image analysis, giving a clearer picture more quickly. As Stefan Voigt and his colleagues point out, this is already beginning to happen through the establishment of the Disaster Management Support Group. 2
Data fusion could also generate interesting insights. 3 Imagine overlaying fresh satellite imagery and seismological data with new live data sources, such as telephony records, geocoded search data, or social media commentary from affected populations. A responder might be able to confirm where the areas of greatest need are or where public disorder is likely to compromise aid efforts. Ushahidi is beginning to explore the potential of this sort of mash-up with its SwiftRiver application.
Diagnostic—Why It Happened
Even when responders have a good snapshot of the extent of a disaster, it is important to understand why a disaster happened and how it is evolving. In rapid-onset disasters, this is especially true when the second wave of mortality—generally caused by displacement and by damage to infrastructure and services—begins to set in. Having a clear picture of why a disaster is leading to population displacement or secondary effects such as disease outbreaks allows humanitarians to react appropriately.
Observation of behaviour on a continuous basis and at a mass scale is challenging. Responders need to identify existing sources of secondary data that are open and freely available (or low cost), or identify ways to crowdsource new data.
One potential solution is to monitor communications. Access to text messaging services and phone call metadata (such as location of callers and length of call) could offer clues as to when and where a displaced population is moving. Another idea would be to monitor social media to get a sense of how populations are reacting to the crisis. Relying on telephony or social media data could, however, present limitations. Phone companies might restrict access to data on privacy or commercial grounds, even when responders are only interested in aggregated metadata, not the content of calls. Government responders might have more access but feel uncomfortable sharing data with nongovernmental organisations (NGOs) or United Nations agencies. And in some emergencies communications infrastructure is damaged, reducing the telephony and social media data being generated in the first place.
Predictive—What Will Happen
Experts in conflict prevention and analysis have been making use of trend analysis in social media for some time. Social media offer analysts large, open, freely available, user-generated datasets that convey the tenor of political debate in a given region, which can warn of man-made disasters such as conflict and politically driven displacement.
Kalev Leetaru has shown that careful analysis of mass media reports has predictive value. 4 For example, although the Arab Spring is often said to have taken the world by surprise, the conflicts that erupted in Egypt, Libya, and Syria were all detectable in their emerging phases by means of social media, as reflected in the reporting of observers such as the International Crisis Group. 5 Conflict analysts were able to give good warning of the conflicts and their potential scale. Humanitarian aid actors were apprised of the probable needs and carried out extensive preparations—organising for refugee reception in Turkey and Jordan, for instance.
Big data is also being used to predict natural disasters. For rapid-onset events, scientists are overlaying traditional sources with social media to broaden datasets. The U.S. Geological Survey monitors Twitter to detect earthquakes with a high degree of accuracy. 6 Other efforts have shown that Twitter can be used to detect or even predict food price surges or cholera outbreaks. 7
Slow-onset natural disasters, such as the impact of climate change in coastal areas, may in future also benefit from similar applications. Governments are trying to seize this opportunity by releasing huge datasets to the public to spur investigation. For instance, in 2014 the White House launched a new website containing more than 100 datasets on coastal flooding. 8
Prescriptive—What We Should Do About It
Good information about the likelihood and likely impact of a disaster can allow responders to intervene to reduce the risk of a disaster occurring or mitigate its impact. For instance, knowing that a flood is likely during an upcoming rainy season, humanitarian actors could dredge a riverbed to prevent flooding, or repair drainage channels that would mitigate the effect of a flood.
One area where mitigation can potentially make use of big data is in disaster preparedness, for instance the prepositioning of emergency supplies; another is disaster response coordination, which offers much more scope for big data to benefit responders.
The need for improved coordination is widely recognized. Humanitarian responses can involve numerous actors, including government, militaries, UN agencies, the Red Cross, NGOs, and so on. More than 900 NGOs responded to the Haiti earthquake in 2010. 9
One basic idea is to make sure everyone responding knows who is doing what, and where (so-called WDWW data). This allows intervention targeting—allocating interventions to designated actors, and resources to those actors. A major challenge in these efforts has been that they rely on aid agencies to provide data manually. If the Red Cross is planning to establish water points in a refugee camp, it is not an effective use of resources if CARE engineers arrive to do the same work. The coordination process relies on both the Red Cross and CARE uploading their plans into the United Nations Office for the Coordination of Humanitarian Affairs (UNOCHA) platform in sufficient detail and comparable formats, allowing planners to see that water needs in that camp will be fully (but not over-) served. The scope for this to go wrong is plain, especially in a typical emergency where communications are poor, human resources allocated to planning and coordination are few, and people are working under stress.
Intervention targeting is an area where big data could offer solutions. Agencies are collecting data about community needs and planned responses. Usually, they are doing this in their own formats for their own purposes. Asking them to re-enter this information in (often multiple) shared platforms may not work, but asking them to allow big data analysts to access their data (in whatever format they have it) will be more palatable. Big data promises solutions that work with unstructured data and extract useful findings from it; software such as Apache’s Hadoop addresses exactly these sorts of problems. Effectively, this type of solution converts private, inaccessible data sources into open, widely available pools.
Coordination also involves creating partnerships between actors. For instance, a local government health department may want to select NGO partners that can restore health services across a wide area and need to select a single partner for each administrative district. Establishing partnerships should ideally be based on criteria such as capacity, competency, and cost-efficiency. However, in an emergency, these partnerships are often established in less optimal ways, relying on factors like availability, branding, and cost (as opposed to cost-efficiency). Big data could offer solutions to this matchmaking problem. Big data applications like Ariba enable matchmaking in business-to-business commodities, for example. 10
Another aspect of coordination relates to the provision and procurement of humanitarian supplies. Aid agencies already preposition emergency supplies. This is done by domestic responders at the national and provincial level, and by international responders in logistics hubs such as Dubai, Nairobi, and Miami. Much of this work is based on best guesses: in the long-term future, big data offers the possibility that it could be done much more efficiently.
One of the most advanced examples from the corporate world is Amazon. A patent filed by the company in late 2013 shows that it plans to begin “anticipatory shipping”—positioning goods where it predicts they will be ordered in the future. 11 By combining data on conflict, seismic activity, climate, infrastructure, population density, and so on, it’s conceivable that much more accurate logistics planning could be viable. For example, when the 2005 earthquake struck northern Pakistan, aid agencies had huge problems in accessing sufficient tents for the 3 million who were displaced. 12 Better predictions about the likelihood of disaster and likely impact could have allowed for much improved preparedness.
Challenges
The opportunities that big data presents to humanitarians are many, but introducing big data concepts and tools to the field will also present challenges. First, humanitarian actors lack many of the skills required to make use of big data. A second challenge revolves around privacy issues. Aid agencies are collecting sensitive personal information all the time: for instance when registering refugees in a camp or admitting patients to a clinic. But how do we make this data more open without violating patient confidentiality? A final challenge is data assurance. When allocating scarce humanitarian resources, responders need a high level of confidence in the basis of their decisions. Convincing funders of the value in using higher volume but less reliable data will be crucial.
Ultimately, big data will surely be brought to bear on humanitarian aid delivery, as on most spheres of human activity. The resulting changes will no doubt affect the structure of the market. Agencies better able to marshal data will benefit as they show more impact with the resources allocated to them. Such agencies could be new entrants with new applications, or incumbents creating or acquiring innovations to be deployed through existing infrastructure. There are already examples both of new entrants and of innovation by incumbents: Give Directly is an interesting new technology-driven entrant, while Oxfam is testing new crowdsourced relief solutions. The field is ripe for investigation and investment.
Footnotes
-
Beale, A., 2014. Big Data: Rules to Live By Interview (13 May 2014). ↩
-
Voigt, S. et al., 2007. Satellite Image Analysis for Disaster and Crisis-Management Support. IEEE Transactions of Geoscience and Remote Sensing, 45(6), pp. 1520-1528. ↩
-
Manyika, J. et al., 2011. Big Data: The Next Frontier For Innnovation, Competition, and Productivity, s.l.: McKinsey Global Institute. ↩
-
Leetaru, K., 2013. Can We Forecast Conflict? A Framework For Forecasting Global Human Societal Behavior Using Latent Narrative Indicators. Urbana: s.n. ↩
-
Gause, F. G., 2011. Why Middle East Studies Missed the Arab Spring. Foreign Affairs, Issue July/August. ↩
-
United States Geological Survey, 2009. Shaking and Tweeting: The USGS Twitter Earthquake Program. ↩
-
United Nations Global Pulse and Crimson Hexagon, 2011. Twitter and Perceptions of Crisis-Related Stress. ↩
-
Lehmann, E., 2014. Can Big Data Help U.S. Cities Adapt to Climate Change?. Scientific American, 20 March. ↩
-
Inside Disaster, 2010. Relief Challenges. ↩
-
Vulkan, N., 2003. The Economics of E-Commerce. 1st ed. Princeton: Princeton University Press. ↩
-
Bensinger, G., 2014. Amazon Wants to Ship Your Package Before You Buy It. ↩
-
BBC, 2005. Pakistan Quake Aid ‘Not Enough’. ↩